Autonomy Talks - Georgia Chalvatzaki: Shaping Robotic Assistance through Structured Robot Learning
Mar 26, 2024Alright, I guess we can get started. Welcome everyone to this week's
systems for irosa
s and machine
autonomy
talk. It is a great pleasure to have with us Georgia Chavasaki, assistant professor and research leader in the intelligentrobot
ic
systems for irosa assistance
group in Tu Darmstadt, Germany. So Something About Herbs received his diploma and doctorate in electrical and computer engineering at the National Technical University of Athens in Greece. Power Seeking interests lie at the intersection of classicalrobot
ic
s and machine learning
and the goal is to develop behaviors that allow mobile manipulator robots to solve complex tasks in home environments where there are looping human situations and I suppose a good example is the one we see on this first slide here, for which she received the emulator grant for AI methods from the German Research Foundation and was also voted as the AI Newcomer in 2021 by the Society of the German information, which is great.
The title of today's talk is Shaping Robotic Assistance through Structured Robotic Learning and is an expanded version of the recent keynote talk she gave at Iris. Personally, I'm very excited to hear more. On the subject, that's why I gave you the stage. Thank you very much for the kind introduction and thank you for inviting me. I am very excited to talk to your group and as we discussed before I will ask if you have questions as I go because you may find similar topics that are not, it may seem like they are disconnected, but I will convince you that they are all connected.

More Interesting Facts About,
autonomy talks georgia chalvatzaki shaping robotic assistance through structured robot learning...
Another
structured
robotlearning
under the umbrella, so yes, my group is called irosa. working for roboticassistance
and my motivation what led me to robotics was when I was around five and six years old and on the weekends we would see the dead zones that would also have Rosie the robot, a mobile manipulator, a robotic assistant to do all the housework, who delivers food to the Judgment family etc. so the vision was to have a robot like this Thiago robot that is delivering this pair to me in this case, so what is the main problem now?
We allow such robots to leave the
structured
environment of the laboratory and enter the real world, which is unstructured and requires safe interactions with humans and the general environment, and I will guide you through five points where we will see that we can actually employ the structure to scaling robotic behavior so that we can have robots that can potentially and hopefully perform tasks like Rosie the robot, but of course growing up I understood that okay, it's not just about having a Rosie the robot in my house doing my home, you know, fixing my At home, there are more pressing events, so yes, to get a little perspective, journalists have been reporting on healthcare workers in many developed countries around the world showing a shocking magnitude of things in crises that effectively threatened effective health coverage. and so it's clear that something is missing here and it's not just about the hospitals.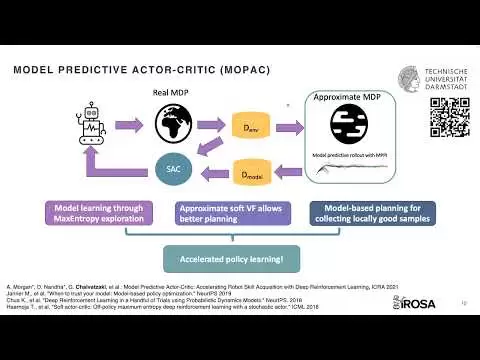
If we analyze some data, we will see that the aging population is constantly increasing, so people over 60 years of age have reached 1 billion and are still increasing. Now, on the other hand, we have Covid-19 and, in addition, we now have digitalization, the options to work from home, which means that many people opt for other better-paid jobs than taking on the job of a transporter, which is very It is stressful and also physically impactful, you know, bodies work and are also dangerous in some cases, which means that elderly people are stuck at home alone and this means only one thing: we need robotic assistance and my vision is that to achieve these linguistic dreams.
By having robotic assistance, we need to unlock the path to body intelligence through mobile manipulation systems and why do we care about mobile manipulation systems? They combine mobility and manipulability so that they can move around the world and manipulate different objects and perform different tasks. equipped with different sensors so that they can perceive the world around them and have a larger workspace since in theory the entire world is their workspace and now that mobile manipulation systems are structured robotic systems, let's reveal what I mean by a structured robot that learns. or structure robot learning in general now if we give a definition that I hope you already know.
Robot learning is the field that uses machine learning methods in robotics to allow robots to acquire skills through imitation and interaction with the environment now in our laboratory what we try. What needs to be done is to take into account the structure of the problem to enable faster, safer and more scalable learning of robot behaviors and what we can do and want to achieve in my group with this structured robot learning. Basically, we have three desired properties for our robots. for our mobile manipulation robots, first coordinated and generalized manipulation skills, second fluid and safe interactions with human robots and finally long-term scalable Horizon behaviors and now I will guide you through these five research areas in which a structure comes into play and gives us a sample of this decision of robotic behaviors for our robots.
Before I go there, I'd like to take a look at this interaction scene with me and my robot again. The robot has to perform this transfer task and to execute this task, the robot. you need to understand the intention of the human being, you need to position yourself in the world, you need to understand how to grab and deliver an object and generally you have to act confidently and let's see now how we can incorporate a structure here into the game, so first we'll see how we can use a framework to learn models for effective human-robot interaction and how in general we can use models to learn models and to plan and see how we can scale robotic behavior in these cases, we will see how we can implement. scene structure to learn longer Horizon tasks and how we can extract the scene from the observations as an instructor from the observations, then we will see how we can use the structure of the robot itself as a basis for learning mobile manipulation and we will also discuss more general how we can learn objectives to perform complex manipulation tasks and finally we will reach the main point of security where we will see how we can learn constraints and use them for safe learning of the interaction between humans and robots.
Well, we'll look at all of these. points in a few different test parts, but I'll try to put them all together and convince you that these are some flavors that we have to achieve to scale mobile manipulation, so why robotic assistance in general, apart from Rosie the robot, another reason was During my PhD I was working with robotic assistants in different scenarios, mainly I was studying models of human behavior to control mobility assistant robots like the one you see here in the image with an elderly person who would have different pathologies that would affect their stability and shape. of work so the objective was to create control strategies for this robot in order to adapt to the specific needs of its user and also act proactively in cases of instability and in general to track the rehabilitation process of the elderly or any user who requires it.
I need to use a robotic narrator, so one of the contributions during my PhD was basically that I realized that people with pathologies, say Parkinson's, for example, actually exhibit a completely different gate cycle than normal, so we had It detects the way its specific user works and adapts the tracking frame that would only take laser points and could give us real-time information about the position velocities and also the phase of the gate and for that we developed an attitude Markov model. structural that would basically monitor the different phases of a human's door and we would be able to adjust the velocity model that we would use for the underlying particle filter that would track his leg separately while for observation we also used probabilistic data Association so that we could ensure that, for example, a particle does not jump far and track another person who is working nearby and this was actually very good because it allowed us to make real-time inferences of the phases of the gate and also extract parameters that would show us how the particle is evolving. rehabilitation process and, of course, with questions.
The question was how can we use this information to actually control the robot, especially if we also take the upper body into account. We were also able to study user stability. I won't go into many details, but if you want you can ask. I and I can tell you how we effectively use camera information and laser tracking to also track user stability, but in general our problem can be framed as a navigation scenario coupled to a human robot in which the robot always has They have to be in front of the human with a desired orientation and a distance and orientation and effectively they must adapt to the specific way of calling, so there are people who take smaller steps that are faster or slower, so the robot has We have to effectively recognize this behavior and adapt accordingly and in fact we have investigated different approaches.
One approach we hypothesize would be very beneficial would be a human-centered model-based reinforcement learning framework, where in this case we would also implement a human motion intention model that would predict at a forward horizon, the user's work intention. and we would use this information in a network that would allow us to learn the basic statistics of this human robot coupled system to extract possible samples of possible actions for our robot to use within. a model predictive controller and take the best action to add it and apply it to our robot and obviously because we learn with modern reinforcement learning, we would add the data and update again this human-robot interaction model and we have shown in simulation that This was actually more beneficial than, for example, a kinematic controller like a leader-follower controller or learning by pure imitation from data we have collected from real demonstrations of older people working with a robotic narrator.
So yes, overall, the interaction between learning and planning is very, very interesting. So as you know, if we focus on this part, I hope you can see my uh, my indicator, this is the standard, let's say deep reinforcement learning, in this particular case, a framework where an agent acts on an environment, collects , explore the environment and collect data According to some exploration strategy, use the data to train our favorite d-parel algorithm which, in the case of suck, is maximum entropy, so there is a lot of randomness, which is something that We don't like it for our robots and also that in general.
In the end, when you want to learn complex behavior, you need to acquire a lot of data, so our idea, and in fact this was developed simultaneously with other approaches, such as a model-based policy optimization, was to use the data that you collect anyway randomly to learn a model and while mbpo approaches would use this model to randomly sample stocks we took a different approach where we said okay with this data we are actually approximating the mdp we are By learning the model, we are learning the reward function, so why not plan on this rough mdp and while planning, you can also explore locally taking, say, the best possible actions, of course subject to fidelity from your model, but also since we learn a value function with our model free agent anyway, we can use this value. works as, let's say, the final cost in our predictive control model and this has been done as an nppi basically, of course, we don't apply any action of this imaginary deployment, but we use the top trajectories to store them in another buffer.
You would mix real data with model-based data and we have shown that this really improves learning a lot in terms of training time. You can see that our approach which we call mobug converges faster compared to mbpo which was the competitive approach and we have also used this method to train a robotic hand in the real world from scratch with these three agents from Dr. Critic Mbpo and Mopac and the first task we saw here is the round valve rotation where the robot just has to grab the Evolve and rotate it until it opens basically and as you can see again Mopac learns faster and also more stable behaviors and then the next task It was a little more challenging becauseWe basically wanted to stress the agent out and actually force him to use all four fingers. because I don't know if you realized before the agent understands in all cases that you can actually use only two fingers to perform these tasks, so in this task we perform a finger activation task, which means that the agent you actually have to grab a The apple that is hanging keep it up so it doesn't fall and rotate it until it reaches the desired orientation and again you can see that the other focuses are actually rotating the apple, sometimes it would fall while Mopac can comply again . the task and it's actually exposing robust behavior, um, but of course one problem with modern reinforcement learning is how can we effectively explore the environment to learn a good world model.
In the previous case, we relied on maximum entropy exploration, but obviously. With robotics, this is not always a good option, so in recent work we took an active exploration perspective, we were inspired by active inference and we studied purely model-based reinforcement learning, yes, so we said especially when we have to explore to learn. Dynamic where rewards are scarce, it is quite problematic because you don't have a concrete signal to judge whether the actions you are taking and what you represent to your world are really true, so our approach was to alter the predictive model. control objective by adding an additional term here that attempts to maximize the information gain between some model parameters and the expected states and the returns given these parameters if policy pi is followed and this expected information can again be seen as a measure of how much the agent expects. learn about the environment by following this policy, and then we can imagine that this goal becomes a maximum if the agent expects to make an observation that will dramatically change its belief about the correct choice of model parameters, then this causes the agent to say curious about the environment that tries to explore it and does this during releases we actually do through our MPC and as you can see we also control the contribution between being gold director or being, let's say, information search with this beta parameter and again We have tested this approach initially in simulation.
We had this tilted table. The target is not given as a state, so the state is not informed about the target. Therefore, the agent will only be informed about the target if we obey. We usually hit the target and get a lot. the maximum reward there otherwise is only driven by the mutual information goal and you can see how this agent is able to cover the information and we were also able to use the same strategy again to train this robot from scratch in the real world simulating more or less the same environment and we have also tested it with different inclinations of this environment, does it work well?
So yes, and we have also tried it with different inclinations and in most cases we were able to solve the task and it was something that we find very encouraging to continue research in this direction for model-based reinforcement learning, so yes, maybe Maybe I would see if anyone has a question for this first part in terms of similar models or would accept a question. now and if you want, you have questions later, I can come back after the end of the talk, if there are no doubts, I will continue and we will move on to the next part, we will see how we can implement the scene itself as um. this is the same structure for learning longer task augmentation and as an application, let's say test, but in this case we're going to use what we call Assembly Discovery.
Now, what is Assembly Discovery? Imagine you have some architect or designer who gives you an arbitrary design and some big blocks and says okay, use these building blocks to fill the shape and this is actually a project we have with the Department of Architecture here in the US. darmsted um so obviously it's a task that requires long Horizon planning and it's also a combinatorial optimization problem because we need to find the placement sequence of these building blocks to meet these arbitrary shapes. You can see that we were arbitrarily sampling some layouts in different similar areas and some random blocks and Basically, we are trying to optimize to feel as much as possible of this layout and we thought it's okay if we also take into account the structure of the scene so that these blocks The construction blocks we had available looked like Tetris blocks, obviously, and we created the scene graphic.
In fact, we can build a graph neural network agent that can be trained with reinforcement learning and we can also deploy the robot in the loop so that we can take into account the feasibility of the robot and whether it can build stable structures and actually learn the process. task sequencing in this case, so what block should I place, where and in what order, and we have also seen that if we implement search during inference, we can generalize quite well; However, since this is a combinatorial optimization problem, it is actually a very challenging task. In terms of exploration, we recently extended this initial approach, say end-to-end, where we train just one DNN reinforcement learning agent in a hierarchical method.
In this hierarchy we have a solution based on a high-level model that is just a mixed integer. linear program solves resource allocation takes a relaxed version of our problem so it doesn't consider many of the constraints that actually exist in the physical world and I'll explain that a little bit more in a moment at the middle level we have the um, the graph-based reinforcement learning agent that now only explores the solutions provided by food at the high level and at the low level, we have a grip and motion planning approach where it simply transforms the desired assembly commands into robot joints. moves because basically this middle agent is actually telling you okay this block has to be placed there and you can just plan and do this assembly so just to have a little bit more information on the high level food and let's see what that would look like this.
If we have these Tetris type blocks, we can imagine that our robot has to play Tetris 3D and we have to complete this area within this yellow layout, so we voxelize the construction area area with the pink, we have the voxels that we have to feel when the green ones are the ones that do not need to be filled because they are outside the area so if we see it as a 2d case we can imagine that in Tetris we normally have to fill a rectangular area but here we only have the pink area, so we solve a program simple mixed integer linear which in this particular case does not care about structural stability, does not consider the robot in the loop nor the task sequence, so this alleviates the need to extract some complex and potentially non-convex objectives for integer linear programming mixed, but we simply fill in the voxels so that they effectively give us a possible set of solutions on what type of block we should place, where now we take these sets of solutions and go to the real world, let's say, we have the same graph that represents the blocks that are unplaced potentially those that are already placed and also the voxels that should be filled or not filled or should remain free and we do several rounds of message passing in our graph neural network and with deployment learning Q We can effectively explore the actions proposed by milk, but now, in this case, our Q function is basically trained to take into account structural stability, since this is part of our reporting function, robotic visibility, since we actually also have another term in our reward. which checks whether or not the robot is capable of executing a collision-free plan and finds, say, the grip that will execute the possible assembly action and effect, it actively learns the sequence of tasks and we can see that if we simply take the heuristic approach of the Milk that does not effectively consider the execution of the movement ends in many conditions, while in our case effectively, if we also use MCTS planning during inference, we can extrapolate to larger structures different types of objects that are used and we can also transfer this to the real world for our robot to run using this digital tweet, so here of course we use external perception, initialize our scene and then open the loop, the top layer of the robot operates the assembly, uh, fortunately, it is able to run it without a lot of big problems and uh.
Yes, we found this very interesting in the direct sense for basic task and movement planning direction and are considering how to extend this to different rearrangement tasks, but of course perception is still an issue so I'll just take a few minutes to show you some. We have good results in terms of vision-based perception, so how can we, without supervision, represent objects in a scene, especially when there are things that come and go, like hands or large scenes like here, a human manipulates different ones? objects of two months of structure to capture so recently we have proposed an information-theoretic approach to answer the revised keypoint discovery, so we draw inspiration from classical computer vision and, in particular, approaches that consider the entropy of images as a way to represent a structure and use entropy in boxes to enforce keypoints to actually represent areas that are represented by these masks and distribute the keypoints in a box so that they can capture as much information as possible which contains an image, but when we are talking about demos or similar videos, this is a sequence of frames, so we also introduced conditional entropy objectives that try to enforce the key point to also cover the new information that will come from the frame before the new. frame and finally, since we also want to temporally learn the dynamics, so the key points to be able to follow the flow of information in a video, we also introduced an information transport loss that would actually impose the key points to reconstruct the information in a sequence. of frames so we introduced three losses for as I said the maximum coverage of the entropy in different frames and their information transport as a mutual information objective and together with some regularizers that would activate or deactivate unnecessary keypoints if for example with a minimum number of the key points, we can contain information that we could, as you can see here, this is our approach, it tracks objects effectively in dynamic scenes, we can also learn to predict their dynamics and here you can see some results also from this data set demonstrated by humans and You can see how the key points basically disappear when the human hand moves away or appear when the human hand appears in the scene or even capture the structure of the thing and again this is promising because we can consider this as a low level representation . for also learning from a demonstration like in this simple test, but we were able to overcome, for example, CNN-based feature extraction for imitation learning, so yes, this was the scene exploiting part.
I don't know if there are any questions for this part, but I would like to move on to the next part which connects with mobile manipulation, finally, yes, mobile manipulation in general is very, very difficult. I have come to understand this over the last three years that I have been here for you dumpster, because the robot has to coordinate effectively, so where should the base be placed, when should we activate the arm, yes, what type of actions we must do and, of course, with a minimum number of actions, so we take a perspective here by considering that decision making is considered hybrid. action and how hybrid actions in mobile manipulation and what I mean by hybrid actions, we can basically consider the optimal based placement scenario where the robot has to effectively position its body, its base in the world, so that the orientation in which case we introduced the continuous part. and the discrete part only that the discrete part is actually conditioned to the continuous part and this actually makes sense because I mean that you need to know where you are located to know if you can reach an object or not and to be able to train it.
We have to use a soft parameterization of Max 3D to allow automatic differentiation and as I said before, this discrete decision variable is connected to the notion ofscope, so the agent must effectively understand whether it is capable of achieving a goal in order to achieve a goal. train this decision variable and for that we were inspired by classical approaches in mobile manipulation that would consider the operational workspace of the robot, that is, all, say, 60 voxelized postures that the agent can achieve and would also give it a certain frequency of yes or No. You can find a solution there now, if we take the operational workspace and consider the floating base scenario, then we can effectively invert this operational workspace and basically cut it to the floor level so we can get the inverse accessibility map that looks like So.
This is so for any arbitrary target 60, we can query and invert these maps and slice them into the ground. You can see that this is of course a voxelized approach, it's quite heuristic and we thought, what if we actually trained an agent on this data set to get a smooth curettability map, so we trained an agent on these local tasks, let's say accessibility, and we acquire this fluid curettability map, however this is still at the locality of the agent and the mobile manipulation is effectively longer. Correct horizon, so the agent has to move around the room, effectively approach an object and, for example, grab it, and to do this we have to transfer this prior knowledge of readability to something longer and for that we introduced hybrid boosted reinforcement learning that allows us to transfer knowledge. and what it effectively means in momentum means that the acute function can be modeled as a sum of residuals and you start by learning your base, let's say task which for us was this soft curitability and any time you need to learn a new task, add, learn just the residue so effectively that it keeps the structure of your previous tasks untapped and everyone learned the missing part to perform the new task and we also discovered that if we add a regularization of the Cooldown Library forward, it gives intrinsic bonuses to the agent so that it can remember, let's say, good actions from previous tasks and this framework is also very interesting because it allows us to handle changing observation spaces and changing reward functions in different tasks like, for example, in this case where a robot has to reach an object, this was the original task, then we moved on to navigating a large room, then we added obstacles, then we wanted to grab an object and set the target and then we changed the training settings again or even found a free space to grab an object where other objects on a table are effectively its obstacles and we were able to transfer these learned readability maps directly to the real world and here you can see how we can adapt, this is how the agent always adapts to changes in the environment, we randomly change the positions of the table and the agent adapts and we can use exactly the same behavior to run reordering tasks so that we can place it effectively when you Know your capacity, you can position yourself and then trigger to select or place or, yes, any task like this, some favors we had was because, when we were training in simulation, this accessibility agent generated subgoals so effectively. that basically tells you your next base position and whether or not you should activate to pick or play something and while we were in the simulation we used our own, let's say, scheduler, in the real world we used the Ros navigation stack, so there was a little more, let's say, for sure. and it didn't allow us to get very close to the table, so we experienced some crashes because of that, but this can be effectively changed if you train with the same strategy or if you change of course your base planner, do you have any questions?
At this point, if there are no questions, I will continue. So we get to the point of the objectives and so effectively, now for mobile manipulation we are only considering these basic pick and place tasks, but manipulation is broader than just Pick and Place and there are tasks that are actually very difficult to learn and they even specify some reward function or they are difficult exploration tasks and you really need human demonstration, some expert demonstrations to show you how to do this, so instead of learning directly. From, say, matching configurations as in kinesthetic teaching, we consider actually learning cost functions or, as we call them, implicit antecedents and using them for motion optimization and to capture multimodality in the demonstrated data, we propose using based models in energy and I will do it.
I'll give more information in a moment, but generally speaking, these energy-based models can be used as implicit antecedents to basically form cost functions because they can capture multimodalities. They are composable because they belong to the exponential family and can be represented in any space, which means that you can actually learn them in the task space and implement differentiables for work topics to evaluate really different ones when you basically optimize the trajectory to evaluate different configurations of robots, so just a quick note on why we call them implicit models, why they are better than explicit. models, so our work was effectively inspired by these success stories seen in generation where energy-based models and diffusion models have outperformed previous explicit models such as variational encoders or generative networks adversaries, because these tend to collapse in some ways or not.
It doesn't represent multimodality in the data well because of the players we use, so we realize that the past works by learning from the demo for motion optimization based on explicit methods, as if it had some distribution that it probably learned from somewhere to sample. some data and then you have your own design cost functions and you basically try to evaluate these initial samples, for example, so our goal was to investigate whether we can use implicit methods in a motion optimization and we show several, let's say, training advances that have. What to do to use it for movement optimization.
I don't know if I need to go into too much detail effectively. You can see that basically an energy-based model contains this term here called energy, which is an unnormalized density that in order to become a distribution, it needs to be normalized and usually this is painful and requires integration of Monte Carlo. Now typically the way we train epms is to basically use contrastive divergence, which is some kind of maximum likelihood estimation where you try to boost positive and negative samples. to create positive and negative energy landscapes and usually this is too strict, it creates some sharp edges, let's say, in your energy landscape.
Now, if we look at the motion optimization approach, we usually have some, for example, previous and possible trajectories. contexts the context could be, for example, a possible objective, location or some objective, for example, liquid mass, liquid that you have to pour and indeed we can see that these antecedents that you may have can be composed into factors, especially if you consider them independent . and now if we take a planning as inference approach, so we have to do a probabilistic perspective, we can effectively form motion optimization as a maximum posteriority problem and we can see here the duality between planning optimization and inference , where while we are in planning we need to evaluate with respect to some cost functions when we consider our energy based models, basically we have to evaluate with respect to some energies and generally our goal is to find optimal trajectories that minimize the sum of some costs that you may have designed by hand, for example, softness. in your trajectories plus some energy that you have learned from some demonstrations and consider some context as I said, putting some amount and effectively we can see the difference of having an explicit prior that samples some trajectories and evaluates them as I said before for some costs compared to have again some samples, they can also come from learned initial distributions, but you effectively evaluate them from a hand-designed terrain composition and cost functions, so yes, explicit priors are not composable, have limited expressiveness and generally They are learned in configuration. spaces, while the previous ones implied as energy-based models are composable because they belong to the exponential family and one can imagine that, for example, distance-based costs can be effectively considered as mahalanobis distances, so they can be composing with energy-based models, they are highly expressive. and you can learn them in the task space as I said before, so we introduced several advances on how you can train these energy-based models to use them for motion optimization.
I'm not going to say all the details, so look at the document, but in essence, we created object-centered representations that we basically produced, this was basically the kind of object-centered approach where we can move, let's say, this ball to the poured and the agent will actually follow up. We can have phase conditioning when we talk about trajectories. which are time dependent, so we can discretize the steps and actually learn phase-conditioned ebms, especially for the poding task, but we can also consider other tasks like I don't know the handovers that have a specific time and we can effectively do score matching to eliminate noise.
We'll talk a little more about this in a bit, but this gives us smoother gradients. We are learning that it is indeed important when we do planning like gpmp and we have also shown that you can integrate other backgrounds as initialization for your trajectories and us. It has been shown that in a toy experiment we can see an initial demonstration of some random planner for different obstacle configurations where we can learn our cost along these trajectories, introduce some additional uh priors and have smooth trajectories over different targets compared to cloning behavior that can be seen collapsing into a medium type of behavior, let's say, and we can also effectively show this dumping task on the robot, where we initially learned from the demonstrations and adding our costs to avoid obstacles that in In this case they are not learned, but one could consider learning as well. obstacles avoidance costs we can perform the pour regardless of how the scene looks good and as I said before the notion of diffusion now I don't know if you follow the new rib updates etc. you will see diffusion models playing. everywhere, so diffusion models are a way to learn some models to generate samples by iteratively moving noisy random samples towards a learned distribution, so it's very interesting because basically a lot of noise is induced at different levels when you implements diffusion. models and the common way to train energy-based models with diffusion is by denoising the score, where we first perturb some initial distribution with some Gaussian noise on different skates to perturb this initial distribution and to sample this distribution in the practice. example, data from our original distribution and then we add some random noise according to the scale of our Gaussian noise and we can estimate the scoring function of this prepared distribution of noise by draining a noise-conditioned ebm by score matching, so that basically you only care about the energy component so just the score is just the probability component of your energy based model and that's okay there are some details about the training loss which is different from the original way of training models based on energy and this is very favorable because it directly gives you the derivative of the energy function and to make inference you have to do a need mcmc with an inverse diffusion process, so I will actually show you in a moment how it is done this in sc3 for robotics, while diffusion has been demonstrated. in images, we have seen it develop in an amazing way when generating realistic images or it is in this space in the image space, so we wanted to bring diffusion to sc3 to train ebms on complex sc3 distributions and for that we introduced fields of sc3 diffusion, ie. a scalar field that effectively provides basically an energy, a value for any arbitrary point living in sc3 and some level of noise, so we learned this energy-based model with score matching fromdenoising as a testbed for a difficult learning task, say a distribution that Consider the task of capturing 60 captures because 60 captures is effectively an open problem.
Typically, standard approaches would learn the variational autoencoder, for example, and try some initial fetches, then implement scheduling and say okay, this graph was good. I will run it, however, by Training with this process I will not go over all the details. I don't want to put too much information and too much math into your mind right now, but we effectively implemented um Elite algebras to do the delivery of um, the derivation of gradients in ETC so that we can effectively follow the diffusion training process and to sample with mcmc Thanksgiving Dynamics and this is very important because since we are implementing stochastic dynamics we only need the gradient of the energy and we do not need to integrate effectively to normalize our distribution and this is what the inference looks like: you start from the reverse process, as we said , augmented diffusion, you start from a very noisy, highly noisy distribution and effectively collapse down to the lowest one. noise level that basically belongs to the convergence to the real distribution, your original distribution and here are some random samples that we have to present.
In theory, you can select, you can sample many more samples, of course you have to parallelize. Fortunately, we are using neural. networks, so this is feasible, this is what the neural network looks like internally, we are also learning the SDF of the object because we found that it is actually useful to take the learning features from the real manifold, say, of the object and then around The variety represents the variety of actual grips and what is important to note now is that by having access to this energy gradient we can effectively use it as a cost function along again with other differentiable costs as before and make grip and movement . optimization in a single optimization pipeline and effectively this allows us, for example, to do just let's say um uh Collision free grafts.
I don't know why this doesn't work well, for example here, as I said, we compose this goal together with the obstacle avoidance goals. so the agent can simply grab the marks and leave them in a respective configuration, but we can also effectively solve pick and place problems, which means that the optimization process can select the catch that is best for performing a placement, especially when we also consider confined environments like these shelf environments which can be considered, let's say, a narrow environment and you can see that the agent selects a herb that would allow it to place the cup in an upward direction on the shelf, considering how we place the cup or how we changed the scene there, so yeah, I'm getting close to closing the talk.
Sorry, it takes a little longer if you're tired. I can also stop, but I would like to ask if there are any questions like what's on your mind right now, feel free to ask anything, eh, I don't know if anyone has any questions, if not I'll end with the important topic of security and we will take a learning perspective on safety in the first place, which is what we wanted to be. able to learn some constraints, in particular when we talk about avoiding self-collisions, when we do whole body control or when we do interaction with a human robot, being able to consult efficiently and very quickly, um, collision points with um, with the other agent, it is very It is very important and while we know that we can implement a signal distance field to represent such collision avoidance objectives, it is actually quite computationally expensive to do them in the real world or not very fine-tuned because I don't know if we use voxelized versions of our objects etc., what we have considered in this case is to take the idea of Deep SDF for approaches that learn to design object distance fields with deep learning and extend them for articulated objects like the robot in this case. and also inspired by, say, Euclidean sdf, we also wanted to be able to adapt these distance fields to arbitrary scales according to the different applications we might need for that, apart from the fact that we consider the pose of the articulated object as input and not just a point we try to understand whether or not it belongs to a manifold, but is also subject to the actual pose of the robot configuration.
In this case we add a trainable um but a regularization and in The feeling of realizing the object in this particular case again is that the robot has a point mass whenever we are very far from the actual manifold or surface of the object and then pushes it down and pushes it down and takes the form of the variety every time we are. they're getting closer to the object of interest and this requires some trainable parameters that really give us this smooth transition and I'll show you later what this looks like at real world implementation time. able with this regularization to approximate a very complex manifold quite well also in any possible configuration and you can see here, for example, for the human manifold, our approach compared to the Deep SDF and the other competing approaches, how much smoother the level sets of our sdfs and how we can effectively learn also a very good um, let's say a refined manifold for our articulated object here is a human and here you can see how effectively, when the robot approaches the human, the manifold scales from a ball until collapsing into the real variety of the human and, of course, this is not enough.
We have shown here that in this paper we can use this learned sdf to effectively and very quickly query for collision avoidance when we do standard operational spatial control, but we want to learn the complex interactions with humans that we want. to be safe and for that we must always take care of our constraints, so we consider reinforcement learning as a problem where we want to learn some tasks, we want to maximize our expected returns subject to some constraints, whether they are learned or again specified by humans and If we consider, say, generalized coordinates, there is a part of the pitch of the robotic state that is controllable and another part that is uncontrollable, we can effectively consider the variety of constraints and we can assume that the constraints we consider are both. equality and inequality constraints, therefore we can also introduce a slack variable in our problem and basically this can also be considered to be inspired by operating space control and null space control.
When considering the manifold constraints, we can especially take the tangent space of our manifold by taking the null space of our Jacobian constraints and we can now alter our original action space into an action space that must always follow the tangent of the restricted manifold. and in this case we always make sure that we do not locally violate the constraints and how we can use this, we can actually use this approach to learn challenging tasks like a differential navigation Drive um where here we consider the differential constraint Drive along with an additional obstacle avoidance constraint with some SDF on this random agent and collision with On these walls and I'll play it, you can see that the agent can reach the red goal by avoiding the agent and still meeting the limitations of the environment and its system, and we can use our ground constraints to effectively learn the dynamic manipulation on these shelves back in the shelf environment and transfer them to the real world without much loss of, say, real Gap performance and effectively we can also implement it with a human in the loop here the task for the robot to deliver this class upward towards the human, the human was instructed to ignore the robot, pretend that the robot is not there, read the source and reach out to take the orange there and, as we can see, the robot can react to the human to ensure safety with a human with himself with a table and holding himself up, so the constraint of the task which was to hand the glass up, um, so yeah, this was my story today about how we can effectively use structure in different components to learn scalable robot behaviors that I have seen this in different scenarios, but my vision is to combine all of this effectively so that mobile manipulation tasks are performed in The real world.
My takeaway message, if I may, is that we must remember that we stand on the shoulders of giants. There has been a lot of work ahead, so we have to use it and combine machine learning with classic robotics. We need to use problem structure because this is the way to scale robotic behaviors in general. We are working mainly with structured robotic systems, so we need to put these inductive biases in our learning algorithms when it comes to the interaction between humans and robots, we need to also take into account the structure of the human being itself and not only consider skeletons and stickmans and effectively learn safe human-robot interactions and finally, I think it is important that we strive to learn how to manipulate mobile devices.
There are many open problems there also in part of perception because this is the path for embodied intelligence. So yes, this was all on my part. Thank you for your attention and I am now open to your questions. Very good talk, many interesting ideas, let's open the stage for questions. You can raise your hand and I will call you or write in the chat and I will read the question for you, let's see if we have any good switches, if not. I could go, okay, I can go first, so it was actually one thing, so it's not really my field, but one thing I wanted to understand is that you tried, you should at the beginning some work that you did in your PhD when you were trying these . things with real people, with real people, so those were patients or people who really needed the robot, now in relation to your interesting slides where you have these five points that guided your talk, where do you think the challenge is, of course you have what to be? a mix of those five, but which of the five is the challenge to be able to quickly provide these services to these people in the future?
I would say that safety is the most important thing right now, safety and reactivity, basically because I mean you can be safe, but if you are not quick enough to react to ensure safety or to act proactively so that safety does not hit a human being, safety can also be acting proactively to help a human being because, for example, the human being is unstable and may fall. therefore in this particular case the agent would have to position itself differently to support the human, we didn't go as far as having such scenarios because obviously the people who participated in the studies couldn't be allowed to actually fall, but this was the general objective and I would say that it is part and parcel of the algorithms, but the other important part is the hardware, so the hardware must allow you to be able to control at high frequency and also that you can have some type of compliance and I think this is a very important part, so yes, I would say this is the most important thing right now.
Okay, great, thanks and out of curiosity, your app is between classic
autonomy
, so you may have the same problems as me. I don't know the autonomous vehicle companies as far as regulations, etc., but are you also close to medicine or these kinds of things that are even more strict, I imagine, like robotic surgery, etc., in a very practical way, do you? how long it takes? for a robot to be approved or what is the procedure if you want to use your robot in a real scenario these days, for home environments let's say, we don't really have the necessary framework right now, so most of the specifications come from the human robot collaboration isos, but these are also the ones used for manufacturing domains and not exactly for cobot law and not exactly for human robot interaction in homes, where there are also ethical restrictions that are more complicated, so I.I would say that at this point we still don't have the unnecessary legal framework to say that this is the process that is problematic and should be fixed at some point. Well, I was suspecting this, but I wanted to be sure it's great. uh, any other questions, I don't see a racial dance, no one, that was because the talk was very clear and also probably yes, it could be clear or not now because, also, it's getting darker in Zurich, I guess on that too there are the people. being sleepy of course, so anyway, if anyone wants to reach out after the talk, if you remember anything or find something interesting, feel free to email me or any of the cultures and yeah, feel freeto communicate and be happy to Answer questions, but I think we're okay, then someone says they'll come to you.
In fact, I also noticed that one of your co-authors studied with me, Nicholas Funk. I think with the Masters together, ah, great, yes, Nicholas. Incredible, very good, say hello for me, I'll tell you it's fine, Georgia, thank you very much again for the great talk. I'll keep you posted with the video link once it's uploaded and all the best for the next one. The best for you and also for the rest of the team, thank you, goodbye, take care.
If you have any copyright issue, please Contact


![[CMU VASC Seminar] Foundation Models for Robotic Manipulation: Opportunities and Challenges](https://i.ytimg.com/vi_webp/akDSG9FsoCk/mqdefault.webp)



